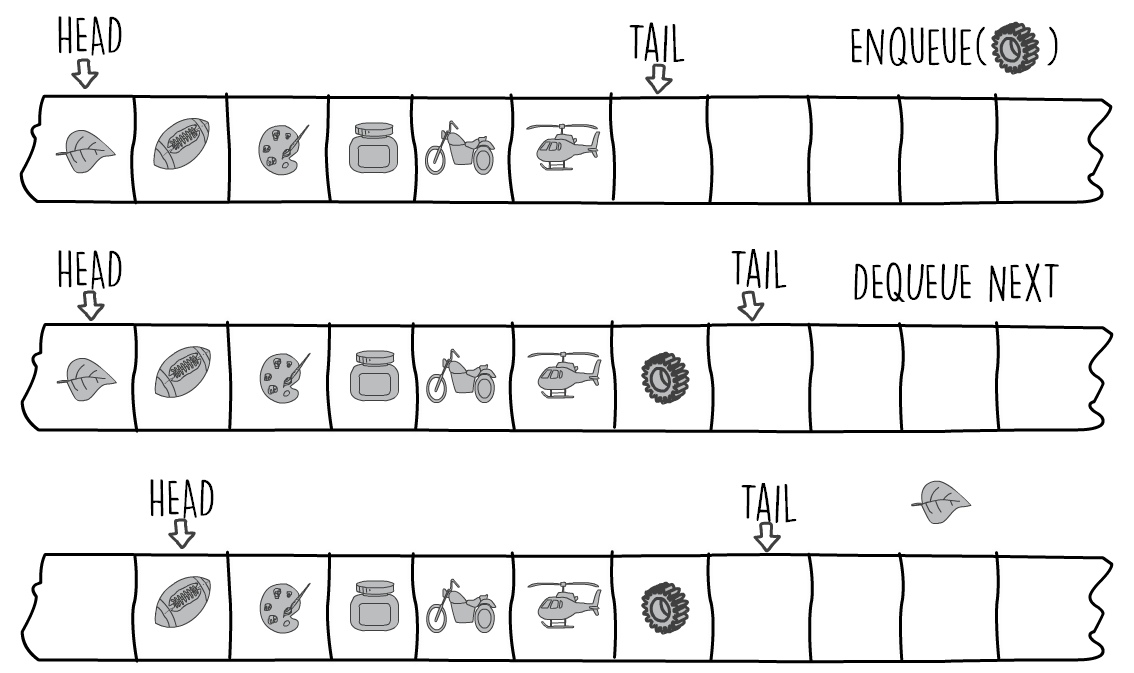
cut a.jar
Home
Not a blog
Publications
Projects
Talks
Contact
Home
Not a blog
Publications
Projects
Talks
Contact