|
My last non-blog post got me thinking about my past technical interviews. I’ve been on the receiving end of a few of these. I remember questions like "How can you build a system where only your cat passes through the door flap?" or "Can you describe your character in 5 words?". For the record, I hated both of these… I really have no idea what they were trying to evaluate.

What about examples of good ones, the ones I really enjoyed working on? I also had a few of those. In this post I’m going to describe a past employer that asked me to write some pseudocode to implement a queue data structure. However, there was a twist… The queue had a fixed maximum size and I had to use an array as a base data structure.
Let’s start with the basics. A queue is a basic data structure used in many algorithms. It allows you to add an item to the tail of the queue (an operation called enqueue) and remove from the head (called dequeue). The way we usually model a queue is by using a doubly linked list, this gives us a constant runtime complexity for both operations. Here’s a nice diagram to explain this: 
Using a doubly linked list, when we need to enqueue, we create a new node and point it to the current tail. Then we get the tail node to point to the newly created node and finally we update the tail pointer to point to the new node. To dequeue an item we do the reverse at the head of the list.
The advantage of using a linked list is that the structure grows dynamically. As long as there is enough memory you can keep on enqueuing items. So why on earth would you use a static structure such as an array to store your queued items? The idea of using an array has advantages. Notice how in the doubly linked list we’re wasting memory. For each item we have to create a container and two memory pointers. For example, if our queued items are 32 bit integers, we would be wasting 4 times the data in just pointers (assuming 64 bit pointers). In addition this constant allocating and freeing of memory space slows things down a little. So how can we model a queue so we don’t have to use all this extra memory pointers? The answer is to use a fixed sized array. The idea is to allocate enough memory for the array at initialization and then use it to store items in a queue like manner. So how would the enqueue and dequeue operations work on an array? How about you ahead and try to write the code for this and then come back to see if you got it right? 
Nice to have you back. Did you manage to do it? Which parts were the hardest? I think the hardest part of the problem is caused by the fact that a queue grows from the tail and shrinks from the head. We can keep two array index pointers, one for the head and one for the tail. When we enqueue an item, we increase the tail pointer. When we dequeue, we increase the head pointer. The next diagram shows this.
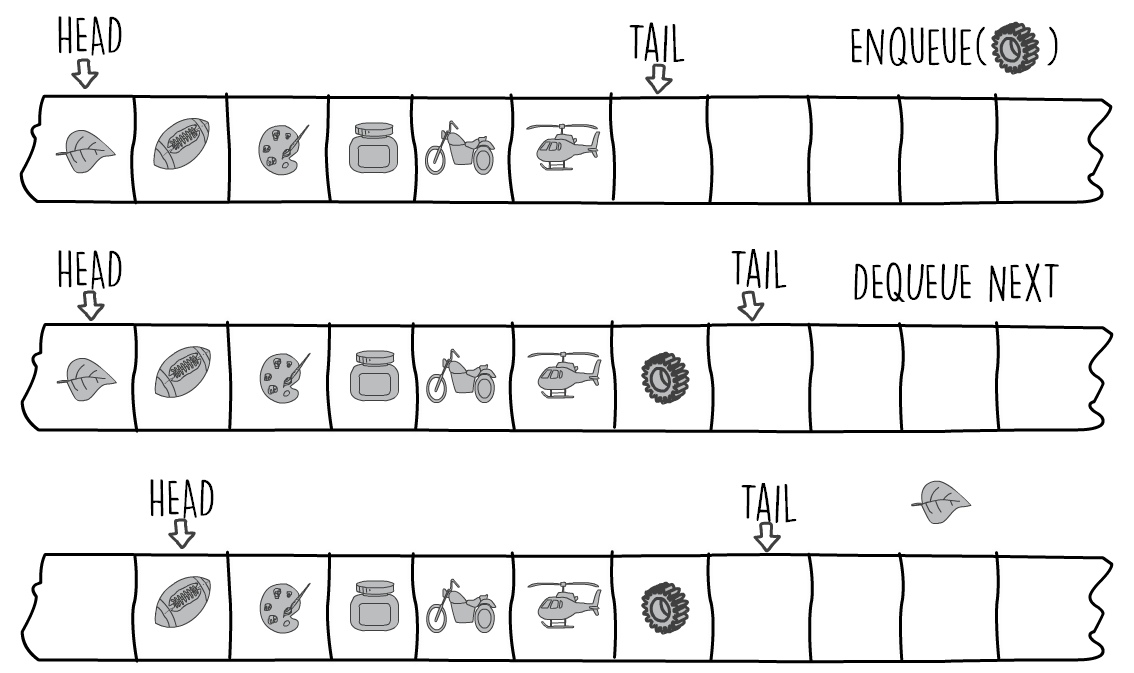
This is simple eh? We always enqueue at the tail position and then increase it. The slight hiccup with our plan is what we do when the pointers reach the end of our array. The next diagram shows this. The tail pointer is at the end of our array with no more space where to advance. However the front of our array is empty and can be used to contain more items. The solution here is to wrap around (the pacman way) and move any pointer that is at the end of the queue to the front. This applies to both the tail and head pointers. 
How do we go about implementing this? We can easily implement the "pacman" wrap around using the mod operator. This is also the way we would implement a circular buffer. The next snippet, in python, shows how we can do this for both the tail (enqueue) and the head (dequeue) pointers. More advanced implementations can also throw errors if the array is full or empty. An array is full or empty when an increment in a pointer results in it having the same position as the other pointer. For example if we increment tail pointer resulting in the same position value as the head one we know that the queue is full. If the head pointer reaches tail pointer then the queue is empty. Both of these checks are not included in the next code to keep things simple.
Did you like this article? You can find more of these data structures and algorithms in my various courses and publications on my publications page. Please leave comments and feedback!

0 Comments
|
