|
Caches should be an easy way of improving performance by bringing data closer to where it's needed... well at least in theory. Most of us have used some sort of caching at one point or another. Commonly reference data is read from DB, stored in local memory and subsequent reads are directed to the fast local memory. The data can either expire or can be swapped out to make room for more heavily used data. But what different flavours of caching exist? How do you decide which technique to use? So what is caching? The following chart shows the main principle being data. It shows the access time on different hardware. The measurements were done a while ago so timing might be a bit off. Still... the gap between disk access and memory is a huge one. The benefits are obvious. Even remote memory access is 1,000 times faster than accessing local disk. The improvement is even more dramatic when comparing remote DBs with local memory. 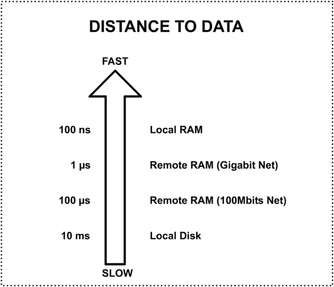 A cache's main purpose is to get data closer to where it's needed. In access terms closer means having faster access to data, not physically closer (see above diagram). This is done purely to improve performance. Caching usually involves 3 actors; a cache client usually consumes data; a cache store holds the temporary data and the underlying storage (or main storage) which stores the complete data set. When a client requires a particular set of data, it first checks if the cache store holds it. If it does the client reads and uses the required data. This is known as a cache hit. When this data is missing from cache, the required data is read from main storage. It is then placed in the cache store, possibly replacing other bits of data. This is called a cache miss. Selecting which data to replace is done using a replacement (or eviction) policy. Replacement policies and Evicting stale data Cache stores have a limited space. They are usually a fraction of the total underlying storage. How do we decide what data goes in and what stays out? A replacement policy decides what is swapped out when a cache is full and new data needs to be added. Ideally when we swap data out, we would like to remove the data that is not going to be used in the near future. Accurate predictions of the near future tend to be quite hard unless you have a large crystal ball. So usually replacement policies use heuristics to try to determine which data is least needed. Widely used policies are:
Timeouts aren't the only mechanism to remove stale data. In our news website example, we could have a system that when new news are added the system automatically expires the older news. This is known as explicit invalidation. Side Caching So you've chosen your cache size, the replacement policy and the cache timeout and you're ready to go... but how do you wire everything together? The way the cache store, client and data store interact together can have a significant impact on performance. Thus, choosing the right cache pattern is a pretty important decision... stacks as high as choosing the right toothbrush. Side caching is probably the most widely used pattern. Its cache client algorithm can be seen below. It's pretty simple logic. If the entry is not found in cache, fetch it from datastore and place it to cache. Note that for simplicity, the cacheStore.put() might swap out another item if the cache is full. Object loadObject(Key key){ Object obj = cacheStore.get(key) if (obj==null OR obj has timedout){ obj = dataStore.get(key) cacheStore.put(key,obj) } return obj } This pattern has the advantage of being very simple to implement. It does however have limitations. Firstly, it clutters the client code with a lot of 'if not in cache' blocks. More importantly, this pattern suffers from a high variance in throughput. Let’s say you have a service which provides a temperature reading for different cities. For a particular city there are tens of thousands of processes using this service, each polling every few seconds, resulting in a constant throughput of around 1,000 requests a second. Getting the temperature from source also takes a few seconds. You decide to use side caching, which should give a temperature result in a few milliseconds when the reading comes from the cache. You also decide to use a timeout of 1 second as a one second resolution is acceptable for the clients. The following chart shows how the throughput behaves in a typical side caching implementation. 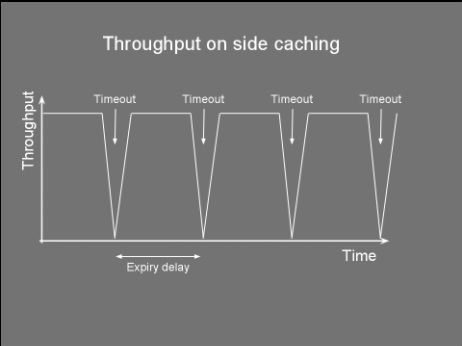 The chart shows that as soon as there is a cache miss the throughput drops dramatically. The process reading the data would experience a high latency whenever there is a miss. This might not be acceptable for some applications. Service clients would get a temp reading in a few milliseconds and then every now and again they'll end up waiting for a few seconds for their request to come back. Quite annoying really. A more serious problem is caused by the concurrent access to the underlying data store. Consider an application where a cache is being used not just to reduce latency but also as a way to reduce load on the datastore. Notice that with the above algorithm there is no locking between the obj==null condition and the datastore.get(). Under high load, a cache miss might result in offloading most of the data requests from cache to datastore. This happens as concurrent requests pile up at the datastore.get(). This would slow things down and if the datastore does not support that kind of load... it could start a chain reaction leading to the end of the universe as we know it (or more likely you having to restart your server). The final problem with this algorithm is the extra load it might put on the network. Consider a setup that has the cache store running on another server. Thus cacheStore.get() and cacheStore.put() result in a remote call. Each cache miss requires two back and forth network messages; One checking if the key is in the cache and the other to put the data in the cache. When the cache miss is detected by two or more clients at the same time, this would result in multiple cacheStore.put() of the same item, wasting bandwidth. So how do we address some of these problems? Read on... Double checked locking Do you also get negative thoughts when you hear 'Double checked locking'? If so, this is because Java developers have tried to use this to implement a fast multithreaded singleton class. Prior to the 'volatile' keyword there was no safe way to implement this (for more info see http://en.wikipedia.org/wiki/Double-checked_locking). Thus for a time this was considered an antipattern. In spite of my negative vibes, DCL is a useful pattern that can be used not just for singletons. The next algorithm shows how we adapt the loadObject method to use this pattern. For simplicity the lock method blocks the current thread on the actual value of the key not on the object itself. Object loadObject(Key key){ Object obj = cacheStore.get(key) if (obj==null OR obj has timedout){ lock(key){ obj = cacheStore.get(key) if (obj==null OR obj has timedout){ obj = dataStore.get(key) cacheStore.put(key,obj) } } } return obj } Using the above we can guarantee that whenever there is an expiry (or invalidation), only one thread gets the value from datastore, reducing the load and some bandwidth. Read-Through What if my cachestore is on another machine and multiple clients access it? What's the best pattern to reduce bandwitdh and latency? Behold the 'read-through' pattern... This pattern delegates the dataStore responsibilities to the cacheStore. The following algorithm shows pseudocode of both the client and cachestore. Notice how we simplified the loadObject method. If the cacheStore returns null, it means the object simply does not exist in both the cache and datastore. cache client: init(){ cacheStore = new cacheStore(dataStore) } Object loadObject(Key key){ return cacheStore.get(key) } cache store: CacheStore(DataStore ds){ dataStore=ds } Object get(Key key){ obj = cacheMap.get(key) if (obj==null or timedout){ obj = dataStore.get(key) cacheMap.put(key,obj) } return obj } The cache store now contains a reference to the datastore. We have moved the 'side-caching' logic onto the cache store. This greatly reduces the bandwidth usage and latency when the cache store is remote. The client now needs to do only one call. This also reduces complexity in the client code. If there is a cache miss, the remote cache store loads it from datastore and stores it locally. The improvement between client side caching and read through is shown in the image below. 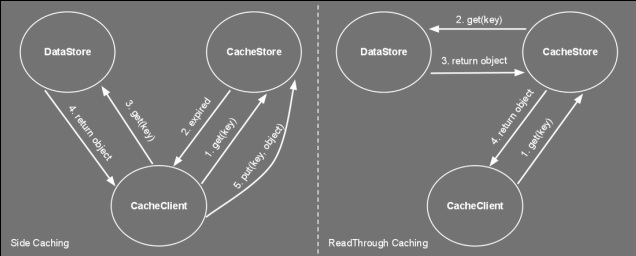 I know... a sequence diagram would have made more sense here... but hey circles and arrows work! Anyways, these circles and arrows show how side caching requires at least five networks messages (even 6 if an additional ack is used) on a cache miss, while read through requires only four. As in side caching we could also improve the read through pattern by adding the double checked locking to the get() method so as to reduce the load on the datastore whenever a miss occurs. Refresh-Ahead This caching pattern tries to address the latency problem whenever a cache miss occurs. Consider again the latency chart shown for side caching. Whenever an item is heavily accessed and expires (or gets invalidated) there will be a pause to wait until the item is reloaded from datastore. Wouldn't it be good to have the reloaded item available before the cache miss happens? The idea behind the refresh-ahead pattern is to have the item refreshed in the background before the item expires. To understand this better we need to introduce the idea of a soft/hard invalidation. A hard invalidation results in a normal cache miss. Whenever an item is hard invalidated it can't be read from cache. A read will query the datastore and replace the cache value. A soft invalidation happens before a hard invalidation. Whenever an item is soft invalidated, it can be still read from cache, but a reload is started in the background to refresh that value. With this in mind the refresh-ahead pseudocode is the following: Object loadObject(Key key){ Object obj = cacheStore.get(key) if (obj==null OR obj is hard invalidated){ obj = dataStore.get(key) cacheStore.put(key,obj) } else if (obj is soft invalidated AND is not being loaded){ scheduleLoad(key) } return obj } scheduleLoad(Key key){ putInQueue(key) } //In separate thread/thread pool consumeQueue(){ while (true){ //Blocks until item is avaliable Key key = loadFromQueue() obj = dataStore.get(key) cacheStore.put(key,obj) } } It’s easy to see how for heavily used keys, the item will always exist in the cache and a cache miss never occurs. This is because the item will get soft invalidated and reloaded before it gets the chance to fully timeout. This following diagram illustrates this concept. 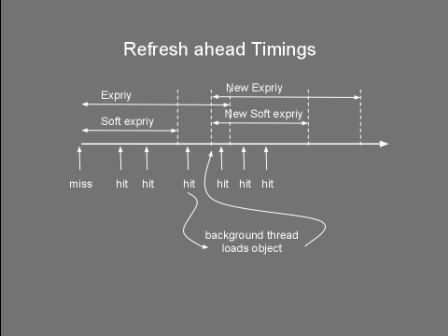 If we now repeat the same exercise for side caching, querying the cache heavily for a particular key we would notice no throughput gaps and our latency would remain low. The following chart shows the result of requesting a particular cache item frequently, not letting the item fully expire.  So there you have it, a few caching tricks and techniques. But which one should you use in your application? In my experience, side caching is best used in batch processing/back office applications. Read through pattern can be applied when the cache store is distributed and/or you want your client code to look cleaner. Refresh-ahead is ideal for low latency, front office or client facing application.
0 Comments
|
