|
A while back I had the pleasure of working with an occasionally grumpy developer. Nothing frustrated Matt as much as badly written code. He used to sit at his desk and from time to time you could hear ‘WTF?!’, ‘What were they thinking?!’, ‘Who wrote this?!!’ and ‘What the hell is this doing?’. I enjoyed pair programming with Matt, not only because he was an excellent developer, but also because he used to come with the funniest terms for how not to do things. Every time he came up with a new phrase for an anti pattern, I opened a text file and wrote it down. Here is some of the stuff he came up with. The Ultimate Unit Test of Doom We have all seen this many times. It’s surprising how often developers manage to fall into this trap. When you come across a unit test starting with an initialisation of a spring context file or even connecting to a database, and then doing 10s of assertions in one test case, you know you’ve come across the Ultimate Unit Test of Doom --insert dramatic music here-- Such tests usually contain only one test case and it might span a few hundred lines of code. It might check if the stored proc exists and then call a service method and expect a table in the database to be populated. It is testing a whole subsystem instead of a unit of behaviour. The next code snippet shows one such example 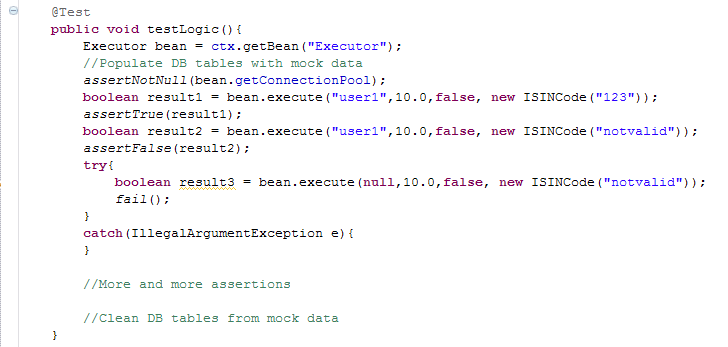
The evangelists of unit testing preach that unit testing is not about testing at all. Unit testing is all about specifying behaviour. When you’re writing your unit test if you’re asking yourself ‘Is the system working as it should?’ you know you’re going down the route of the ultimate unit test of doom. Instead you should be asking yourself questions such as ‘If I put these inputs in this interface, once I have an implementation for it, it really ought to be returning me these kind of outputs’. More than a testing framework, unit testing is a thought process which makes you think ahead about how to build the small units of your software and how they interact together. Pass the Banana We came across this anti pattern when we were trying to understand how a system property was propagated through the system. The ‘Banana’ was a boolean flag that was passed as a startup main argument. The flag was passed from one method to the other, from class to class until it got read and used at the bottom of the stack. The following code illustrates an example of a ‘Pass the Banana’. 

Most developers would see the above and ask ‘Why isn’t startThreadPool a system property and whatever class needs to access it can just read it directly?’. The thing is, such bad practises aren’t usually written by just one person. They usually evolve over time through incremental changes by different developers. The above example most likely started with simple implementation where the main method started the thread pool directly. As the system got more complex and larger, the call to start the thread pool moved further down the layers. Each developer kept passing the banana every time he added a new class or method. Solving these kind of issues and keeping code complexity down is not an easy task especially when you have a large team and tight schedules. Allocating time for refactoring and improving code quality in each sprint is key. A code analyser tool helps, but its not enough. It also comes down to each developer’s attitude and willingness to improve code quality. If each developer took one step in the right direction, instead of a ‘pass the banana’ pattern, it would he the ‘happy hour’ pattern... The one where developers are down the pub instead of debugging horrible code. Martin Fowler wrote a good article on opportunistic refactoring at: http://martinfowler.com/bliki/OpportunisticRefactoring.html The Monolithic method of Death This is quite simple to explain. It’s a method that takes 7 arguments or more, is called ‘process’ or ‘execute’,is about 200 or more lines of code and has horrible multiple nested ifs and loops. You know what I mean... we’ve all come across one of these... 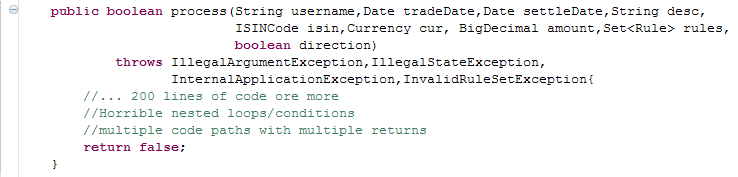
In my experience people underestimate the impact on productivity of bad code and tech dept. It’s also very hard to explain to non technical business people that a part of the system needs redeveloping. Why should I pay you to write code that is going to do exactly what the current code already does? It is a very valid argument. In an ideal world it should never get to at point where a system needs to be reimplemented. Coding should be an evolution. Small incremental improvements that make the code more modular, readable and easy to scale. Unfortunately this is hardly ever the case. Schedules are tight, pressure builds up and corners are cut. Again there is no technical fix for this. It all boils down to methodology and individual attitudes and some of the team dynamics. Are the correct development practices being followed? Is there enough time in each sprint for refactoring and reducing tech debt? Is there good team communication?
Poo in a File This is not really an anti pattern. It’s more something Matt did and made some people laugh. One morning I updated my code from subversion and I noticed a new file called 'pooinafile.txt'. When I opened this I found the text 'poo' in it. It turned out that Matt was testing why his bit of code wasn't reading from the file system due to some permission issues. He had created the file and committed by mistake. Since then we kept on using the phrase every time someone committed a file that didn't belong in the repository. Matt, wish you had named your file something a bit more exciting...
2 Comments
A while ago I was presented with a classic “we need to reduce our bandwidth usage” problem. Of course there are a number of techniques to reduce bandwidth, but in order to use the most appropriate tool I needed to understand my problem domain. In this particular application, the network messages consisted of a large set of Longs and Integers. The problem was made harder by the requirement of a low latency server response. So how do you quickly pack these sorts of data types to take less space? Examining the data I found out that 90% of the Longs would fit in an integer and some of them in a short. Most systems would represent Longs, Integers and short in 8, 4 and 2 bytes respectively. Surely a long that fits in a short doesn’t require 8 bytes. But how would the receiver determine how many bytes that number is using? Enter Variable Length Quantity, VLQ in short. VLQ has been around for a while. Wikipedia says WAP used it and google’s protocol buffers use a similar format. In short VLQ, as its name implies, makes the data type’s size variable. Instead of having a number of datatypes (long, int, etc..), each with a fixed byte size, we could have a marker in our byte stream to show where the data unit starts and finishes. The following diagram illustrates the concept. The diagram shows an example where three units of data encoded with a marker signalling where each unit ends and another starts. 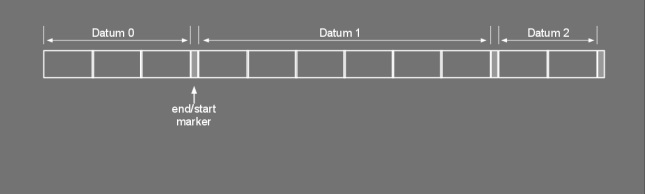 A popular scheme is to have the marker represented by the last bit of each byte. In this scheme, this bit is reserved as a marker as it is not used as part of the value. The most significant bit can be set to 1 if more bytes are to come, 0 otherwise. This can be illustrated with an example. Consider the integer 11733. In a most significant first system, the receiver would see a byte stream appear in the following order (left to right) 00000000 00000000 00101101 11010101 Using the most significant bit as a marker, the receiver would get: 11011011 01010101 When the receiver/reader sees the first byte, it knows that more bytes are available since the MSb is set to 1. The receiver/reader stops once it notices a 0 in the first bit. At that point it can remove the markers and compact the received bytes to construct the original data type. At the sender/.writer side, the leading zeros are discarded, and the stream is broken down in 7bit segments. All bytes are then marked with a 1 in their MSb except the last one. The ACME guide on how to build your own VLQ reader and writer. Let’s start with the reader. You’ll need a way to read and remove the marker from the stream and a way to compact the bytes together. The first part is the easiest. There are probably many ways to do this, but a quick way to test your marker is to ‘AND 128’ your byte and then checking if the result is zero or not: 11011011 AND 10000000 = 10000000 Having a result of 0 means you’ve reached the end. All of this can be written as: boolean end = ((bytesRead[i] & 128) == 0); Removing the markers is easier as you can just OR the rest: 11011011 OR 011111111 = 01011011 Translating to code this gets: bytesRead[i] &= 127; Rebuilding the original stream involves some thinking. The solution I came up with is to left shift the bytes into place. You start from the last byte read and OR it to a 0 place holder (int, long, etc). Then you left shift the next to last by 7 bits and OR it to the place holder. Do the same with the next byte but left shift it by 14 and so on until you have no bytes left. This is the algorithm I came up with (where x is the result integer): int j = 0; int x = 0; for (int i = values.length-1; i >= 0; i--){ x |= values[i] << ( 7*j ); j++; } Writing a sender/writer turns out to be simpler than the reader. The sender simply makes space and applies the marker bit. To make space, we need to segment our stream in 7 bit parts. Again the shift operators come in handy. By continually masking the first 7 bits and right shifting them away, we can build an array of bytes to write/send (i is the integer to write): int j = 0; while (i != 0){ bytesToWrite[j] |= i & 127; i >>>= 7; j++; } Notice how it’s using the unsigned right shift. This is to avoid getting stuck in an infinite loop if the number is negative. To write the bytes (or send over network), we’ll have to start from the back since the receiver is expecting the most significant byte first. When writing we then simply mark all but the last bytes with a 1 in their top bit i.e.: bytes[i] |= 128; Download There you go. You can now build your own VLQ reader/writer. Oh hold on... you can also just use this open source one: https://sourceforge.net/projects/vlqstream/ Caches should be an easy way of improving performance by bringing data closer to where it's needed... well at least in theory. Most of us have used some sort of caching at one point or another. Commonly reference data is read from DB, stored in local memory and subsequent reads are directed to the fast local memory. The data can either expire or can be swapped out to make room for more heavily used data. But what different flavours of caching exist? How do you decide which technique to use? So what is caching? The following chart shows the main principle being data. It shows the access time on different hardware. The measurements were done a while ago so timing might be a bit off. Still... the gap between disk access and memory is a huge one. The benefits are obvious. Even remote memory access is 1,000 times faster than accessing local disk. The improvement is even more dramatic when comparing remote DBs with local memory. 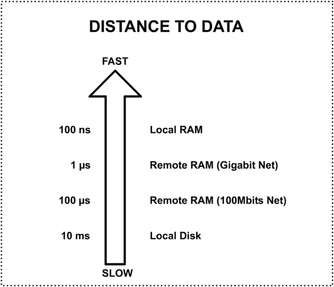 A cache's main purpose is to get data closer to where it's needed. In access terms closer means having faster access to data, not physically closer (see above diagram). This is done purely to improve performance. Caching usually involves 3 actors; a cache client usually consumes data; a cache store holds the temporary data and the underlying storage (or main storage) which stores the complete data set. When a client requires a particular set of data, it first checks if the cache store holds it. If it does the client reads and uses the required data. This is known as a cache hit. When this data is missing from cache, the required data is read from main storage. It is then placed in the cache store, possibly replacing other bits of data. This is called a cache miss. Selecting which data to replace is done using a replacement (or eviction) policy. Replacement policies and Evicting stale data Cache stores have a limited space. They are usually a fraction of the total underlying storage. How do we decide what data goes in and what stays out? A replacement policy decides what is swapped out when a cache is full and new data needs to be added. Ideally when we swap data out, we would like to remove the data that is not going to be used in the near future. Accurate predictions of the near future tend to be quite hard unless you have a large crystal ball. So usually replacement policies use heuristics to try to determine which data is least needed. Widely used policies are:
Timeouts aren't the only mechanism to remove stale data. In our news website example, we could have a system that when new news are added the system automatically expires the older news. This is known as explicit invalidation. Side Caching So you've chosen your cache size, the replacement policy and the cache timeout and you're ready to go... but how do you wire everything together? The way the cache store, client and data store interact together can have a significant impact on performance. Thus, choosing the right cache pattern is a pretty important decision... stacks as high as choosing the right toothbrush. Side caching is probably the most widely used pattern. Its cache client algorithm can be seen below. It's pretty simple logic. If the entry is not found in cache, fetch it from datastore and place it to cache. Note that for simplicity, the cacheStore.put() might swap out another item if the cache is full. Object loadObject(Key key){ Object obj = cacheStore.get(key) if (obj==null OR obj has timedout){ obj = dataStore.get(key) cacheStore.put(key,obj) } return obj } This pattern has the advantage of being very simple to implement. It does however have limitations. Firstly, it clutters the client code with a lot of 'if not in cache' blocks. More importantly, this pattern suffers from a high variance in throughput. Let’s say you have a service which provides a temperature reading for different cities. For a particular city there are tens of thousands of processes using this service, each polling every few seconds, resulting in a constant throughput of around 1,000 requests a second. Getting the temperature from source also takes a few seconds. You decide to use side caching, which should give a temperature result in a few milliseconds when the reading comes from the cache. You also decide to use a timeout of 1 second as a one second resolution is acceptable for the clients. The following chart shows how the throughput behaves in a typical side caching implementation. 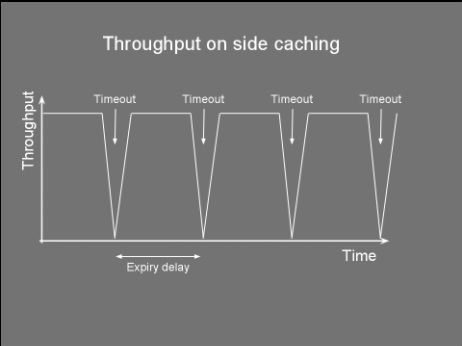 The chart shows that as soon as there is a cache miss the throughput drops dramatically. The process reading the data would experience a high latency whenever there is a miss. This might not be acceptable for some applications. Service clients would get a temp reading in a few milliseconds and then every now and again they'll end up waiting for a few seconds for their request to come back. Quite annoying really. A more serious problem is caused by the concurrent access to the underlying data store. Consider an application where a cache is being used not just to reduce latency but also as a way to reduce load on the datastore. Notice that with the above algorithm there is no locking between the obj==null condition and the datastore.get(). Under high load, a cache miss might result in offloading most of the data requests from cache to datastore. This happens as concurrent requests pile up at the datastore.get(). This would slow things down and if the datastore does not support that kind of load... it could start a chain reaction leading to the end of the universe as we know it (or more likely you having to restart your server). The final problem with this algorithm is the extra load it might put on the network. Consider a setup that has the cache store running on another server. Thus cacheStore.get() and cacheStore.put() result in a remote call. Each cache miss requires two back and forth network messages; One checking if the key is in the cache and the other to put the data in the cache. When the cache miss is detected by two or more clients at the same time, this would result in multiple cacheStore.put() of the same item, wasting bandwidth. So how do we address some of these problems? Read on... Double checked locking Do you also get negative thoughts when you hear 'Double checked locking'? If so, this is because Java developers have tried to use this to implement a fast multithreaded singleton class. Prior to the 'volatile' keyword there was no safe way to implement this (for more info see http://en.wikipedia.org/wiki/Double-checked_locking). Thus for a time this was considered an antipattern. In spite of my negative vibes, DCL is a useful pattern that can be used not just for singletons. The next algorithm shows how we adapt the loadObject method to use this pattern. For simplicity the lock method blocks the current thread on the actual value of the key not on the object itself. Object loadObject(Key key){ Object obj = cacheStore.get(key) if (obj==null OR obj has timedout){ lock(key){ obj = cacheStore.get(key) if (obj==null OR obj has timedout){ obj = dataStore.get(key) cacheStore.put(key,obj) } } } return obj } Using the above we can guarantee that whenever there is an expiry (or invalidation), only one thread gets the value from datastore, reducing the load and some bandwidth. Read-Through What if my cachestore is on another machine and multiple clients access it? What's the best pattern to reduce bandwitdh and latency? Behold the 'read-through' pattern... This pattern delegates the dataStore responsibilities to the cacheStore. The following algorithm shows pseudocode of both the client and cachestore. Notice how we simplified the loadObject method. If the cacheStore returns null, it means the object simply does not exist in both the cache and datastore. cache client: init(){ cacheStore = new cacheStore(dataStore) } Object loadObject(Key key){ return cacheStore.get(key) } cache store: CacheStore(DataStore ds){ dataStore=ds } Object get(Key key){ obj = cacheMap.get(key) if (obj==null or timedout){ obj = dataStore.get(key) cacheMap.put(key,obj) } return obj } The cache store now contains a reference to the datastore. We have moved the 'side-caching' logic onto the cache store. This greatly reduces the bandwidth usage and latency when the cache store is remote. The client now needs to do only one call. This also reduces complexity in the client code. If there is a cache miss, the remote cache store loads it from datastore and stores it locally. The improvement between client side caching and read through is shown in the image below. 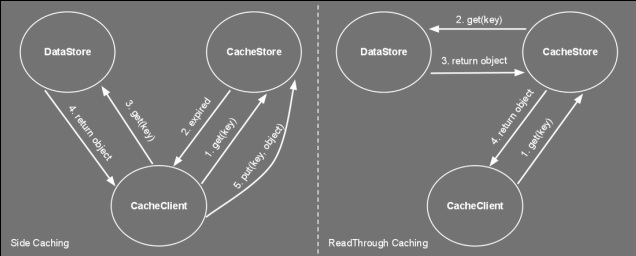 I know... a sequence diagram would have made more sense here... but hey circles and arrows work! Anyways, these circles and arrows show how side caching requires at least five networks messages (even 6 if an additional ack is used) on a cache miss, while read through requires only four. As in side caching we could also improve the read through pattern by adding the double checked locking to the get() method so as to reduce the load on the datastore whenever a miss occurs. Refresh-Ahead This caching pattern tries to address the latency problem whenever a cache miss occurs. Consider again the latency chart shown for side caching. Whenever an item is heavily accessed and expires (or gets invalidated) there will be a pause to wait until the item is reloaded from datastore. Wouldn't it be good to have the reloaded item available before the cache miss happens? The idea behind the refresh-ahead pattern is to have the item refreshed in the background before the item expires. To understand this better we need to introduce the idea of a soft/hard invalidation. A hard invalidation results in a normal cache miss. Whenever an item is hard invalidated it can't be read from cache. A read will query the datastore and replace the cache value. A soft invalidation happens before a hard invalidation. Whenever an item is soft invalidated, it can be still read from cache, but a reload is started in the background to refresh that value. With this in mind the refresh-ahead pseudocode is the following: Object loadObject(Key key){ Object obj = cacheStore.get(key) if (obj==null OR obj is hard invalidated){ obj = dataStore.get(key) cacheStore.put(key,obj) } else if (obj is soft invalidated AND is not being loaded){ scheduleLoad(key) } return obj } scheduleLoad(Key key){ putInQueue(key) } //In separate thread/thread pool consumeQueue(){ while (true){ //Blocks until item is avaliable Key key = loadFromQueue() obj = dataStore.get(key) cacheStore.put(key,obj) } } It’s easy to see how for heavily used keys, the item will always exist in the cache and a cache miss never occurs. This is because the item will get soft invalidated and reloaded before it gets the chance to fully timeout. This following diagram illustrates this concept. 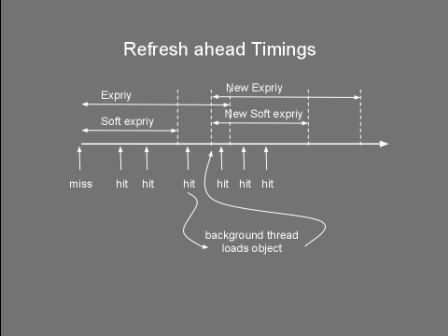 If we now repeat the same exercise for side caching, querying the cache heavily for a particular key we would notice no throughput gaps and our latency would remain low. The following chart shows the result of requesting a particular cache item frequently, not letting the item fully expire. 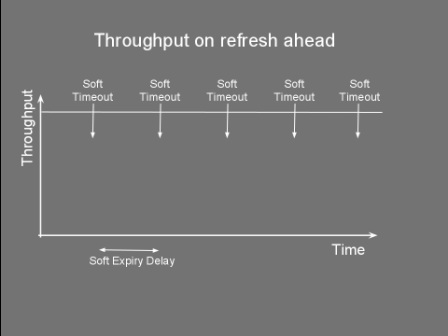 So there you have it, a few caching tricks and techniques. But which one should you use in your application? In my experience, side caching is best used in batch processing/back office applications. Read through pattern can be applied when the cache store is distributed and/or you want your client code to look cleaner. Refresh-ahead is ideal for low latency, front office or client facing application. |
